程序猿三部曲之白银时代
之前在某篇公众号文章中,看到工资10K、15K、20K的Java程序员应该掌握的技术。大致对应着初、中、高级开发人员,所以我打算针对这三个阶段,写三篇文章,一边学习,一边总结。
曾经读过王小波的时代三部曲,分别是《青铜时代》、《白银时代》、《黄金时代》,遂借用来类比程序员的三个阶段。
1 HashMap和ConcurrentHashMap有什么区别?
HashMap是传统集合下的类,ConcurrentHashMap是并发集合下的类。除此之外,它们之间还有各种不同之处:
- HashMap本质上是非同步的,即HashMap不是线程安全的,而ConcurrentHashMap是线程安全的。
- HashMap性能比较高,因为它是非同步的,任意数量的线程都可以同时访问它。而ConcurrentHashMap性能比较低,因为有时候线程需要在ConcurrentHashMap上等待请求。
- 当一个线程正在迭代HashMap时,如果有另外一个线程试图对这个HashMap的元素进行新增或者修改,我们将得到运行时异常 ConcurrentModificationException。然而,我们在迭代ConcurrentHashMap时执行任何修改都不会出现任何异常。
- HashMap的key和value可以为null,ConcurrentHashMap不允许,否则会报运行时异常NullPointerException.
- HashMap 是在 JDK 1.2 中引入的,而 ConcurrentHashMap 是由 SUN Microsystem 在 JDK 1.5 中引入的
2 synchronized关键字
synchronized是Java中的关键字,是一种同步锁。它修饰的对象有以下几种:
- 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
- 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
- 修饰一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象。
- 修饰一个类,其作用的范围是synchronized后面括号括起来的部分,作用的对象是这个类的所有对象。
3 volatile关键字
1 | public class NoVisibility { |
NoVisibility可能会持续循环下去,因为读线程可能永远都看不到ready的值。甚至NoVisibility可能会输出0,因为读线程可能看到了写入ready的值,但却没有看到之后写入number的值,这种现象被称为“重排序”。只要在某个线程中无法检测到重排序情况(即使在其他线程中可以明显地看到该线程中的重排序),那么就无法确保线程中的操作将按照程序中指定的顺序来执行。当主线程首先写入number,然后在没有同步的情况下写入ready,那么读线程看到的顺序可能与写入的顺序完全相反。
3.1 volatile原理
Java语言提供了一种稍弱的同步机制,即volatile变量,用来确保将变量的更新操作通知到其他线程。当把变量声明为volatile类型后,编译器与运行时都会注意到这个变量是共享的,因此不会将该变量上的操作与其他内存操作一起重排序。volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取volatile类型的变量时总会返回最新写入的值。
在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此volatile变量是一种比sychronized关键字更轻量级的同步机制。
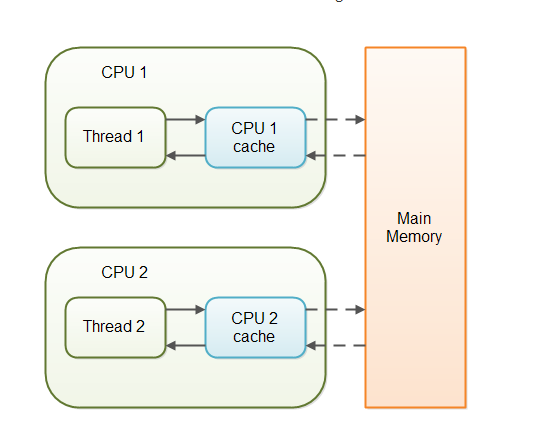
当对非 volatile 变量进行读写的时候,每个线程先从内存拷贝变量到CPU缓存中。如果计算机有多个CPU,每个线程可能在不同的CPU上被处理,这意味着每个线程可以拷贝到不同的 CPU cache 中。
而声明变量是 volatile 的,JVM 保证了每次读变量都从内存中读,跳过 CPU cache 这一步。
3.2 当一个变量定义为volatile之后,将具备两种特性
- 保证此变量对所有的线程的可见性,这里的“可见性”,如本文开头所述,当一个线程修改了这个变量的值,volatile 保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。但普通变量做不到这点,普通变量的值在线程间传递均需要通过主内存(详见:Java内存模型)来完成。
- 禁止指令重排序优化。有volatile修饰的变量,赋值后多执行了一个“load addl $0x0, (%esp)”操作,这个操作相当于一个内存屏障(指令重排序时不能把后面的指令重排序到内存屏障之前的位置),只有一个CPU访问内存时,并不需要内存屏障;(什么是指令重排序:是指CPU采用了允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理)。
3.3 volatile 性能:
volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。
4 堆和栈的区别,堆中存放的是什么,栈中存放的是什么?
4.1 堆空间
Java堆空间被Java运行时用来为对象和JRE类分配内存。每当我们创建一个对象时,它总是创建在Heap空间中。垃圾收集在堆内存上运行,以释放没有任何引用的对象所使用的内存。在堆空间中创建的任何对象都具有全局访问权,并且可以从应用程序的任何地方引用。
4.2 栈内存
Java Stack内存用于线程的执行。它们包含特定于方法的值,这些值存在时间很短,并引用从该方法引用的堆中其他对象。堆栈内存总是按照后进先出(LIFO)的顺序引用。每当调用一个方法时,就会在堆栈内存中为该方法创建一个新的块,用于保存本地原语值并引用该方法中的其他对象。方法一结束,该块就变为未使用的,并可用于下一个方法。与堆内存相比,堆栈内存大小要小得多。
4.3 栈和堆申请空间后系统的响应
- 栈:只要栈的剩余空间大于所申请的空间,系统将为程序提供内存,否则将报异常提示栈溢出。
- 堆:操作系统有一个记录空间内存地址的链表,当系统收到程序的申请时,会遍历链表,寻找第一个空间大于所申请空间的堆节点,然后将节点从内存空闲节点链表中删除,并将该节点的空间分配给程序。对于大多数操作系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的对节点的大小不一定正好等于申请的大小,系统会自动地将多余的那部分重新放入到链表中。
4.4 Java 程序中的堆和栈内存
1 | package com.journaldev.test; |
下图显示了程序运行中堆空间和堆内存的引用,以及它们如何用于存储基元、对象和引用变量。
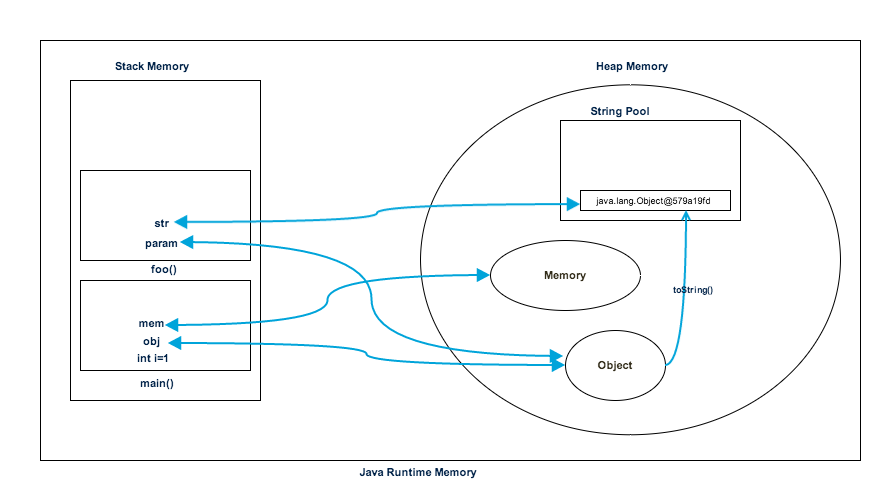
- 当我们运行该程序,系统会将所有运行时类加载到堆空间中。当在第一步执行main()方法时,Java Runtime会创建栈内存以供main()方法线程使用。
- Line 2定义局部变量,它会被创建并存储到main()方法的栈内存中。
- Line 3 new了一个Object对象,Object对象会在堆空间创建,而栈内存保存对象的引用obj,同理,Line 4也是一样的过程。
- 当我们在Line 5调用foo()方法时,栈内存会在顶部创建一个块以供foo()方法使用。
- 由于Java是按值传递的,因此在Line 6处的栈内存块中创建了对Object的新引用。
- 在Line 7创建一个字符串,它进入堆空间中的字符串池,并在foo()堆空间中为它创建一个引用。
- foo()方法在Line 8终止,此时分配给foo()的堆栈内存块变为空闲。
- 在Line 9,main()方法终止,为main()方法创建的堆栈内存被销毁。此外,程序在此行结束,因此Java Runtime释放所有内存并结束程序的执行。
4.5 Java堆空间和栈内存的区别
基于上面的解释,我们可以很容易的得出以下Heap和Stack内存的区别。
- 栈内存仅能被一个线程执行,堆空间可以被程序中所有部分使用;
- 每当创建一个对象时,它总是存储在堆空间中,栈内存包含对它的引用。栈内存只包含本地原始变量和堆空间中对象的引用变量;
- 存储在堆中的对象是全局可访问的,而堆栈内存不能被其他线程访问;
- Memory management in stack is done in LIFO manner whereas it’s more complex in Heap memory because it’s used globally. Heap memory is divided into Young-Generation, Old-Generation etc, more details at Java Garbage Collection;
- 堆栈内存是短暂的,而堆内存从应用程序执行开始到结束都存在;
- 我们可以使用JVM的
-Xms和-Xmx选项来定义堆内存的启动内存和最大内存。我们可以使用-Xss来定义栈内存大小; - 当堆栈内存已满时,Java 运行时会抛出 java.lang.StackOverFlowError,而如果堆内存已满,则会抛出 java.lang.OutOfMemoryError: Java Heap Space 错误;
- 与堆内存相比,堆栈内存非常小。由于内存分配 (LIFO)的简单性,与堆内存相比,堆栈内存非常快。
资料:Java Heap Space vs Stack - Memory Allocation in Java
5 字符串池
顾名思义,java中的String Pool就是一个存储在Java Heap Memory中的Strings池。我们知道 String 是 java 中的一个特殊类,我们可以使用 new 运算符创建 String 对象,也可以在双引号中提供值。
5.1 Java中的字符串池
下面这张图很清楚的解释了String Pool在java堆空间中是如何维护的,以及当我们使用不同的方式创建String时会发生什么
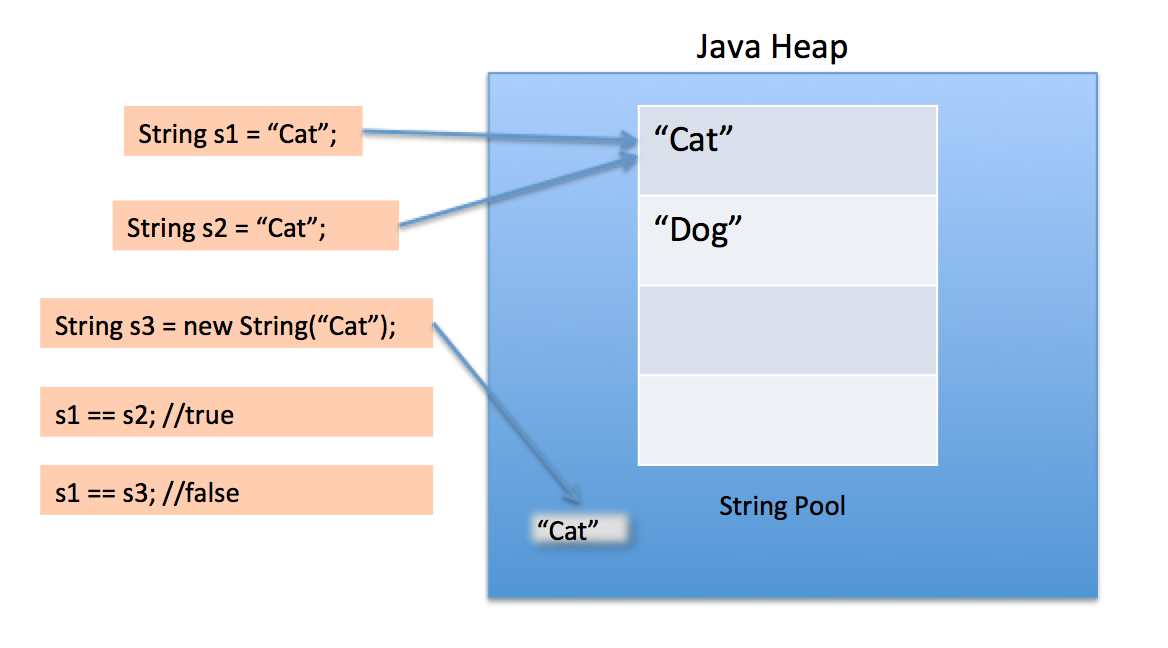
当我们使用双引号创建一个字符串时,它首先在字符串池中寻找具有相同值的字符串,如果找到则返回引用,否则在池中创建一个新的字符串,然后返回引用。但是使用new运算符,我们强制String类在堆空间中创建一个新的String对象。我们可以使用 intern() 方法将其放入池中,或者从字符串池中引用另一个具有相同值的 String 对象。
1 | package com.journaldev.util; |
输出:
1 | s1 == s2 :true |
5.2 在字符串池中创建了多少字符串对象?
有时候在java面试中,你会被问到一个关于String pool的问题。例如,在下面的语句中创建了多少个字符串对象?
1 | String str = new String("Cat"); |
首先在堆空间创建一个“Cat”对象,在栈内存创建str,并指向堆空间的“Cat”对象;然后检查堆空间中的字符串池中查看是否存在“Cat”对象,如果存在,则将new出来的“Cat”对象与字符串池中的“Cat”对象联系起来。若不存在,则在字符串池中创建“Cat”对象,并将堆中的“Cat”对象与之关联起来。
6. IO和NIO的区别
NIO是为了弥补IO操作的不足而诞生的,NIO的特性包括:非阻塞I/O,选择器,缓冲以及管道。其中管道(Channel)、缓冲(Buffer)、选择器(Selector)是NIO的三大主要特征。
管道(Channel):它就像传统IO中的流,到任何目的地(或来自任何地方)的所有数据都必须通过一个Channel对象。
缓存(Buffer):一个Buffer实际上就是一个容器对象。Java的每一种基本类型都有一种缓冲区类型:
1 | byte----ByteBuffer |
- 选择器(Selector):用于监听多个管道(Channel)的事件,使用传统的阻塞IO时我们可以方便的知道什么时候可以进行读写,而使用NIO非阻塞通道,我们需要一些方法来知道什么时候通道准备好了,选择器证实为这个需要而诞生的。
IO和NIO的主要区别:
- IO是面向流的,NIO是面向快(缓冲区)的。
IO面向流的操作是一次一个字节的处理数据。一个输入流产生一个字节,一个输出流消耗一个字节,这样的操作就导致了IO对数据的读取和写入效率低下。
NIO面向块的操作是一次产生或消耗一个数据块。这样按照数据块进行数据处理就明显比按照字节处理数据快得多,同时数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动,这就增加了处理过程中的灵活性。总的来说,NIO采取了“预读”的方式,当你读取某一部分数据时,他就会猜测你下一步可能会读取的数据而预先缓冲下来。
- IO是阻塞的,NIO是非阻塞的。
传统的IO中一个线程调用read()或write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再做任何事情。
而NIO使用的是一个线程发送读取数据请求,没有得到响应之前,线程是空闲的,此时的线程可以去执行别的任务,不会像IO中的线程那样只能等待响应完。
虽然从上面可以看出NIO是为了弥补IO读取数据效率慢这个缺点而诞生的,但是NIO也有其自身的缺陷,NIO是面向缓冲区的操作,这样的话就必须考虑一个问题,NIO在对缓冲区的数据进行处理之前必须对缓冲区数据的完整性进行判断,如果数据不完整的话,NIO的读取就不存在任何意义,因此NIO每次数据处理之前都要检测缓冲区数据的完整性。
如果管理的是成千上万个连接,但是这些连接每次只是发送少量的数据,例如我们常用的聊天服务器,这时候选择NIO处理数据可能是个很好的选择; 如果是少量连接,而这些连接每次都要发送大量的数据,这时候就应该选择IO对数据进行操作。
未完,待续...