Arrays.binarySearch()方法详解
背景:我想校验一个指定的String字符串,是否存在于另一个String数组中,选择Arrays.binarySearch()方法实现,代码如下:
1 | String[] item = {"0","1","16","1591","1594","1596"}; |
运行结果:
1 | not exists |
很直观的能看到item数组里面存在字符串1591,为什么程序运行的结果却是找不到该元素呢?
首先来看一下源码:
1 | /** |
注意,注释上提到了两个重点:
- 使用二分查找算法在指定数组中搜索指定对象;
- 在调用此方法之前,必须根据元素的自然顺序(如通过sort(Object[])方法)将数组按升序排序。
也就是说,数组不是遍历每一个元素,与目标值做对比,校验是否相同,而是通过二分查找算法,先找到数组中间的元素,与目标值做比较:如果目标值大于中间值,则继续比较数组后半部分的元素;如果目标值小于中间值,则继续比较数组前半部分的元素;如果等于,那么就直接返回中间元素的数组下标。因此在调用此方法之前,要先对数组进行升序排序。
1 | private static int binarySearch0(Object[] a, int fromIndex, int toIndex, |
源码中,是中间值通过(low + high) >>> 1
的方式获取的。
这是一个在二分查找算法中常见的代码片段。low 和 high 通常表示搜索范围的下界和上界。mid 是下界和上界的中间值,通过 (low + high) >>> 1 计算得出。
这是由于在Java中,+ 运算符对于整数是按照整数算术运算(即舍去小数点)来执行的。这可能会导致整数的溢出。例如,如果 low 是 -1000000000,而 high 是 1000000000,那么 low + high 的结果将会是 -999999999 + 1000000000,这将导致整数溢出。
而使用 >>>(无符号右移运算符)则可以避免这个问题。位运算中,右移运算符 >> 对于负数会将移位后的左侧填充部分填充为该数的符号位(即负数的话填充为1,正数的话填充为0)。而 >>> 是无符号右移运算符,无论该数是正数还是负数,都会将左侧填充部分填充为0。
所以 (low + high) >>> 1 的结果就是 low + high 的值除以2的整数部分,无论 low 和 high 的值是多少。
拿到数组的中间元素后,通过int cmp = midVal.compareTo(key)的方法比较中间元素和目标值。
compareTo() 方法按字典顺序比较两个字符串(比较基于字符串中每个字符的 Unicode 值)。
接下来回到最开始的问题中,通过调试发现,中间元素16与目标值1591比较,结果cmp=1,也就是说比较的结果居然是16大于1591。
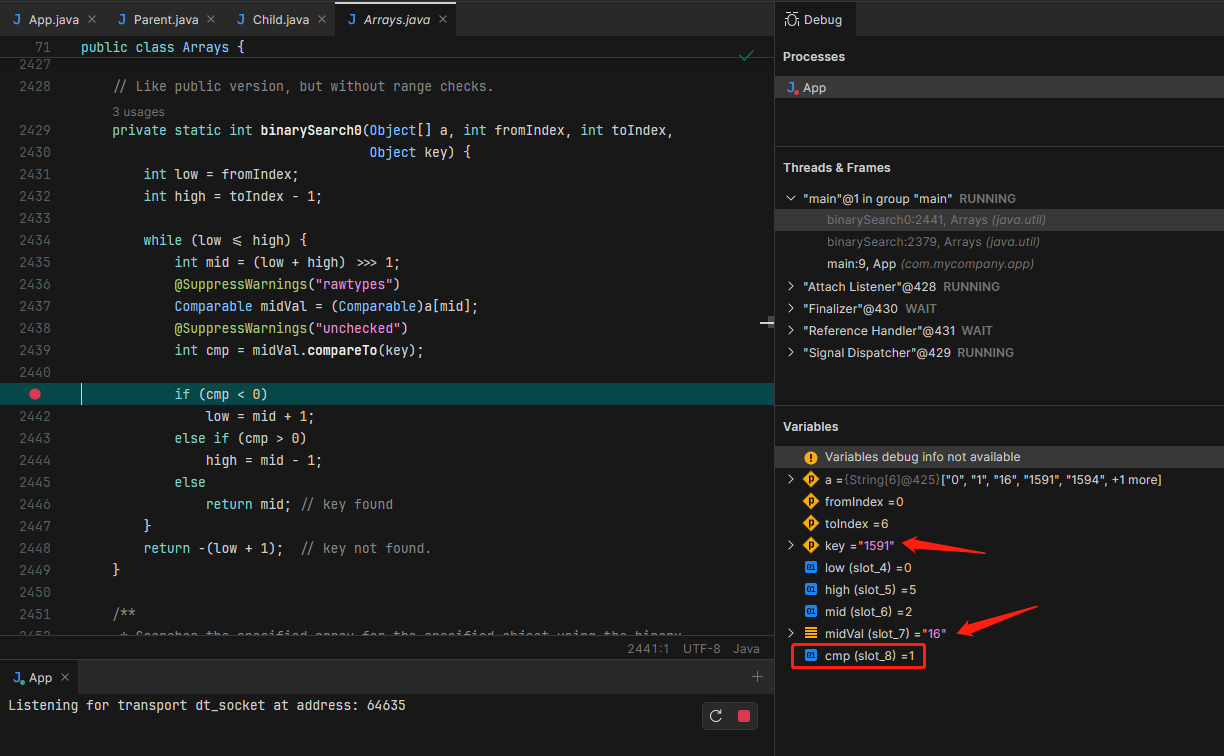
由于比较的结果大于0,因此
mid-1,接下来会拿数组左边部分的值与目标值做对比,而16左边的几个元素不存在1591,因此最终结果是在数组中找不到与目标值一致的元素。
这是因为,16和1591都是字符串类型,而非数值类型,字符串类型通过compareTo()
方法进行比较,是比较两个字符串相应位置字符的Unicode值。
1 | /** |
引申:但是要注意的是,这只适用于两个字符都属于基本字母或数字的情况。如果字符包含其他字符(比如特殊字符、标点符号等),或者涉及非数字字符,那么结果可能不会如你所预期。例如,如果'A'和'中'(Unicode值为65296)进行相减,结果将会是-38321,这显然不是我们期望的结果。因此,在进行这种操作时,一定要确保字符的取值范围和你的预期相符。
至此,文章开头 1591为什么在目标数组中
{"0","1","16","1591","1594","1596"}
匹配不到的问题,原因就是如此。